
CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection
by
 , , , and
, , , and
Femi Emmanuel Ayo
1,
Joseph Bamidele Awotunde
2 ,
,
Olasupo Ahmed Olalekan
1,
Agbotiname Lucky Imoize
3,4,* ,
,
Chun-Ta Li
5,* and
Cheng-Chi Lee
6,7,* 1
Department of Mathematical Sciences, Olabisi Onabanjo University, Ago-Iwoye 120107, Nigeria
2
Department of Computer Science, Faculty of Information and Communication Sciences, University of Ilorin, Ilorin 240003, Nigeria
3
Department of Electrical and Electronics Engineering, Faculty of Engineering, University of Lagos, Akoka, Lagos 100213, Nigeria
4
Department of Electrical Engineering and Information Technology, Institute of Digital Communication, Ruhr University, 44801 Bochum, Germany
5
Bachelor’s Program of Artificial Intelligence and Information Security, Fu Jen Catholic University, New Taipei City 24206, Taiwan
6
Research and Development Center for Physical Education, Health, and Information Technology, Department of Library and Information Science, Fu Jen Catholic University, New Taipei City 24206, Taiwan
7
Department of Computer Science and Information Engineering, Asia University, Taichung City 41354, Taiwan
*
Authors to whom correspondence should be addressed.
Mathematics 2023, 11(8), 1899; https://doi.org/10.3390/math11081899
Submission received: 20 March 2023
/
Revised: 9 April 2023
/
Accepted: 14 April 2023
/
Published: 17 April 2023
(This article belongs to the Special Issue Network Security in Artificial Intelligence Systems)
Abstract
:A keylogger is a type of spyware that records keystrokes from the user’s keyboard to steal confidential information. The problems with most keylogger methods are the lack of simulated keylogger patterns, the failure to maintain a database of current keylogger attack signatures, and the selection of an appropriate threshold value for keylogger detection. In this study, a combinatorial-based fuzzy inference system for keylogger detection (CaFISKLD) was developed. CaFISKLD adopted back-to-back combinatorial algorithms to identify anomaly-based systems (ABS) and signature-based systems (SBS). The first combinatorial algorithm used a keylogger signature database to match incoming applications for keylogger detection. In contrast, the second combinatorial algorithm used a normal database to detect keyloggers that were not detected by the first combinatorial algorithm. As simulated patterns, randomly generated ASCII codes were utilized for training and testing the newly designed CaFISKLD. The results showed that the developed CaFISKLD improved the F1 score and accuracy of keylogger detection by 95.5% and 96.543%, respectively. The results also showed a decrease in the false alarm rate based on a threshold value of 12. The novelty of the developed CaFISKLD is based on using a two-level combinatorial algorithm for keylogger detection, using fuzzy logic for keylogger classification, and providing color codes for keylogger detection.
MSC:
08A721. Introduction
A keylogger is a type of spyware that keeps a log of keystrokes from the user’s keyboard. A keylogger, sometimes called a keystroke logger, is a program installed on a computer system to collect and steal information based on the keys pressed by the user [1,2]. A keylogger is used to keep records of confidential information through the keystrokes from the keyboard, to then perform a malicious attack [3,4]. A keylogger stores all the keystrokes from the keyboard into a log file and periodically sends the file to the attacker’s email. A keylogger can be used for good or bad practices. An example of a useful application of a keylogger is tracking employees’ activities to control misconduct that could cause damage to the company [5,6,7]. On the other hand, a keylogger’s most harmful application is to record login credentials and use the record to perform malicious attacks.
Keyloggers are a current and growing risk to a user’s privacy since they can operate in user space, quickly upload data to distant servers, and distribute data [8,9]. They can be used in several ways and employ a wide range of diverse approaches. The main usage of keyloggers has been subverted in order to be used for nefarious ends that compromise user privacy, particularly that of online users. Keyloggers are programs that record keystrokes or screenshots and save them into files without the user’s knowledge and proper authorization. Most keyloggers now available are regarded as “legal” programs, and they serve a variety of lawful and legal purposes, including monitoring how young people use the Internet and identifying instances of unethical computer use in the workplace [10]. However, they are largely taken away from their original and proper use, when used maliciously. Sadly, one of the main uses for keyloggers now is stealing user credentials for various online payment methods [11,12].
In most network-based systems, the problem of how to exchange information safely without an attacker eavesdropping has become a major research area. The existing algorithms for the security of information exchanges in distributed systems are vulnerable to keyloggers, which could lead to the loss of private information [13]. Similarly, the emergence of cloud-based systems has added a new challenge to the probability of keeping private information from other cloud users. Cloud-based systems now use a trusted cloud computer to protect the sensitive data received from different users. This trusted cloud computer keeps the data received from different users private from keyloggers by adding noise to the data and then sends the private data to each user. Each user then updates its local data by using the private data it received from the cloud. This process ensures the privacy of the data when data is being shared between the cloud and the data’s owners [14]. The issue of keeping information private in network-based and cloud-based systems is one of the motivating factors for the development of a keylogger detection method.
Keyloggers often make an effort to blend in, and, unlike other forms of malware, they have no impact on how computers operate. Despite this, they can still pose a serious threat to the organization to which the information system belongs and the user’s privacy. Keyloggers can take screenshots, and they can record screenshots of the user entering passwords or other private information on their keyboard. The keyloggers’ source then receives this information. The increased use of the Internet has led to users downloading numerous applications and attachments that contain viruses or keyloggers. In contrast to viruses, keyloggers do not spread across the infected device, as they are mainly designed to record the keystrokes of the infected device [15,16,17]. Like other malware, keyloggers have some peculiar behaviors that can be easily simulated into patterns [18]. A signature database of keyloggers can be collected and periodically updated to include all available keyloggers. This signature database can be used to perform file operation matching for keylogger detection.
The number of keylogger attacks keeps increasing because of limited research on the simulation of patterns that correspond to keylogger signatures. In addition, there is no effective method for the detection of keyloggers due to the high false alarm rate [19,20,21]. Moreover, the failure to maintain a database of current keylogger attack signatures and the selection of an appropriate threshold value for keylogger detection remain a challenge. Classical malware detection methods are not suitable for keylogger detection due to their lack of pattern matching ability. Hence, there is a need for effective keylogger patterns’ simulation and detection methods to prevent the negative impacts of keylogger attacks on information systems. In this study, “keylogger patterns” refers to the signature of the keylogger malware in capturing the keystrokes of the users, while “keystrokes” refers to the users’ actions. Hence, a combinatorial-based fuzzy inference system for keylogger detection was developed to solve the identified keylogger problems. The challenges of effective methods and patterns’ simulation for keylogger detection lead to the need to highlight the contributions of this study:
- the automatic simulation of keylogger patterns with ASCII-coded sequences;
- the use of a back-to-back combinatorial algorithm for keylogger detection and analysis;
- the use of a fuzzy inference system to categorize keyloggers into their severity levels;
- the provision of color codes for keylogger detection.
2. Background and Related Work
Before discussing the related works on keylogger detection techniques, it is necessary to discuss the background of the developed and modified algorithms for keylogger detection. All the classes of keylogger detection methods, as represented in the literature, along with their different limitations, are also discussed.
2.1. Combinatorial Algorithm
The major constraint in bioinformatics is where the concept of the combinatorial algorithm first emerged, which involves looking for a recognized sequence in a database of sequences. The combinatorial algorithm can be referred to as combinatorial pattern matching, which is very good for comparing sequences. It is used to find a given pattern p in a text sequence t. The combinatorial algorithm needs two inputs to output the required pattern.
For example, if t = ATGGTCGGT and p = GGT, then the result of the combinatorial algorithm that matches the pattern p in t would be positions 3 and 7. The following mathematical models apply to the combinatorial algorithm. The two inputs are the known ptern t and the specified normal pattern p. The process scans the substring of characters in length of increasing order, , starting at position i. If then the occurrence of the pattern is said to be found. In this study, the combinatorial algorithm is considered suitable for keylogger detection since, unlike other malware, keyloggers have some particular types of behaviors that can be easily simulated into patterns.
The combinatorial algorithm is used in the context of pattern matching to match a given keylogger pattern to a predefined database of normal user actions. The task of keylogger detection can use the concept of the pattern matching algorithm for the analysis of unknown keylogger commands from the network activities. The combinatorial algorithm uses many distance measures to estimate the distance between the keylogger pattern and the normal patterns.
2.2. Fuzzy Logic
A multi-valued logic called fuzzy logic is described as having truth values encompassing all arbitrary transitional values between 0 and 1 [22]. Fuzzy logic has emerged as a prominent idea in most classification systems for resolving uncertainty and precise segmentation. Fuzzy logic is, therefore, best suited to controlling instability in an unstable system. Furthermore, using fuzzy logic to classify keyloggers can capture the overlapping degrees of sensitivity between keyloggers and typical patterns.
Fuzzy logic consists of the input layer, the inference engine layer, and the output layer. The input layer is made up of the fuzzy membership set for the defined problem. Each member of the fuzzy set has the degree of its membership described with linguistic variables. The inference engine layer is the processing engine for the fuzzy inference system. The inference engine communicate with the rule base that is defined by the fuzzy inputs and their linguistic variables for decision making. The inference engine uses the root mean square method to combine the fuzzy inputs and evaluate the output. The output layer uses the center of gravity method to defuzzify the result of the inference engine to arrive at the final predictions.
2.3. Keylogger Detection
Researchers have developed several solutions in recent years for keyloggers’ detection [23]. These solutions can be mainly classified as signature-based detection or anomaly-based detection [24,25]. The signature-based method employs known keylogger patterns as a baseline for future keylogger detection. In contrast to the anomaly-based approach, which simulates normal behavioral patterns, a certain amount of departure from these typical patterns is regarded as keylogging [24]. Back-to-back combinatorial algorithms were created in this study to integrate anomaly-based and signature-based detection techniques. Keyloggers are similarly divided into hardware and software keyloggers [9,26,27]. Hardware keyloggers are devices attached to the keyboard of the computer. The design of an automatic detection method for hardware keyloggers can be very difficult and, thus, needs a manual verification method [9]. Software keyloggers are more common than their hardware counterparts because they can be remotely installed into the computer system. The following are some of the main keylogger methods in the literature.
Recently, in response to a survey of keylogger attacks in the banking industry, the authors in [9] offered some solutions. They identified the theft of private information as the top danger a bank or its customers face. The survey presented the key procedures and solutions of the keyloggers’ process, from capturing screenshots to extracting relevant information about the victim system. The authors concluded that one solution is not enough for keylogger detection. The authors affirmed that there is still a need for possible improvements in the available keylogger detection methods.
In [28], the authors developed a mobile keylogger detection method based on the Support Vector Machine (SVM) algorithm. The purpose of the developed SVM algorithm is to block keylogger access to sensitive data that could lead to loss of information. The developed SVM algorithm consists of three components: permissions gathering, a permission analyzer, and a detector. The permissions gathering component collects the list of permissions for all installed applications, and the permission analyzer identifies the set of permissions and storage levels retained by each of the applications. Finally, the detector differentiates applications with normal and abnormal permissions for keylogger detection.
The authors in [26] developed a touchlogger method to profile users’ information. The authors recorded every activity performed on touch devices by users into different user profiles. The authors collected the profiles of normal and intrusive users. The two user profiles can then be fed into machine learning classifiers to detect keyloggers. Secondly, attackers can use the user profiles harvested by the touchlogger to gather private information from the victim system. The advantage of the study is that the authors directly recorded every keystroke on the touch devices, instead of inferring information about the keystrokes. However, the authors do not provide any formal method for keyloggers’ detection.
The authors presented an updated framework to identify keyloggers using a machine learning approach [18]. First, all the features of keylogger detection are extracted and inserted into the database using an I/O hook. An I/O hook is a mechanism for recording all the activity sets of all applications running in the system. The mechanism checks the time between a keystroke and the output generation in the target application. A delay in output generation could mean that a keylogger has intercepted and stolen some information. The behavioral patterns of different keyloggers that use the time delay calculation are recorded in the database. The SVM was then deployed to detect the presence of a keylogger in the system based on the extracted patterns. The disadvantage of the developed framework is that it can only work on the Windows operating system. However, the developed framework is effective for keyloggers’ detection.
In [2], the authors presented a novel approach to unprivileged keylogger detection. The authors observed that most of the current keyloggers run in user space and do not need any permission for execution. The presented novel approach is focused on detecting user space keyloggers and protecting information systems from malicious keystroke logging. The authors simulated all the normal user activities of the I/O processes and compared the simulated activities with other activities to detect keyloggers. The results showed that all keyloggers followed the same operational processes of recording and forwarding keystrokes from the target system to the address of the attacker. The test results demonstrated the effectiveness of the devised approach for keylogger detection without any false positives.
A hook tracer was created by the authors in [29] to automatically identify and analyze keyloggers using memory forensics. The developed hook tracer monitors each activity in the system memory and compares each system activity with a set of functions commonly used to describe keylogger activities. If any of these activities are found to match the list of keylogger activities, then the activity is reported as a keylogger. The developed hook tracer was found to enable an automated, scalable analysis of keylogger detection.
The authors introduced the anti-hook approach in [30] to scan all procedures and static executables for keylogger detection. This study focused on anti-hook technology, which completely scans the system in various circumstances to identify processes employing hooks, while keeping in mind the keyloggers’ organizational processes to safeguard personal confidentiality and privacy. Any suspicious file can be easily found at any application level using this method. The method involves a lot of calculations and has a significant false positive rate.
The authors in [31] presented a keylogger detection approach using a decoy keyboard. The developed decoy keyboard is a novel malware detector that is accessible to both normal users and attackers. The developed decoy keyboard requires no previous knowledge of keylogger patterns for detection. The method used a decoy keyboard to simulate the operations of the physical keyboard, intended for keyloggers to intercept. The decoy keystrokes were delivered to the keylogger based on a timing model that simulates the behavior of a physical keyboard in the decoy’s keystrokes. The results showed the decoy keyboard to be effective with good detection accuracy.
Similarly, the authors in [21] developed a keylogging inference attack on air-tapping keyboards in virtual environments. The authors presented a keylogging inference attack to gather inputs from the users on air-tapping keyboards. The study used regular hand patterns to infer keystrokes when typing in the air. The authors built a pipeline to rebuild the user input with three probable attack scenarios where the attacker obtains the hand movement of the users. Their attack pipeline took as its input the hand movement of the victim and produced a set of input inferences as outputs. The study provided the first of its kind for inference attacks on air-tapping keyboards for virtual reality devices. The developed method was based on the reconstruction of the victim’s hand movement and did not need any user profile, making it generic for various situations and attacker abilities. The test experiments showed that the developed inference attack achieved the best accuracy for inferring the keystrokes from the user’s hand movement. The limitation is that the study is focused on building keyloggers rather than keylogger detection.
Furthermore, the authors in [19] presented malware security evasion techniques. The authors considered the features normally exhibited by malware to create a keylogger. Therefore, they developed a keylogger based on the considered features. The developed keylogger was built to collect information about the screenshots, keystrokes, and backdoor creation in the infected system. The backdoor creation method was used to evade the leading Windows security mechanisms that can detect keyloggers. The authors tested the developed keylogger in a real environment through different websites as a proof of concept. The test results showed that the keylogger successfully gathered confidential information about the user and evaded Windows 10 firewalls, user account control, and antivirus detection. The limitation is that the study focused on building keyloggers rather than keylogger detection.
A behavior-based detection method utilizing a kernel-level framework for memory and execution profiling was presented by the authors in [32]. The authors presented a brand-new detection method built on fine-grained memory write pattern profiling. Their method aimed to mine sensitive information effectively through data harvesting. The authors used KLIMAX to demonstrate the viability of their strategy, which used an infrastructure at the kernel level for memory and execution profiling. The provided technique can be applied to platforms that are used in real life, with both proactive and reactive detection. The results from experiments with actual keyloggers demonstrated the potency of this approach. The method is suitable for massive malware analysis and classification and produces no false negatives. However, malware evasion strategies that hide or postpone data leaks do not affect this detection method.
The authors in [33] developed an anomaly-based detection technique for keyloggers. The driving force for the authors’ development of an anomaly-based detection technique that could be included in signature- and log-based detection methods is based on the observation that the majority of keylogging detection methods now in use operate primarily at the client level or by employing signatures at the host and checkpoint levels. The created method offers a precise way to identify keyloggers using traffic analysis.
In [34], the authors developed a keylogger detection using a dendritic cell algorithm. An immune-inspired dendritic cell algorithm (DCA) was employed in the study to identify the presence of keyloggers in an infected host system. The proposed algorithm’s objective is based on correlations between several activities, including keylogging, file access, network connection, and time interactions. The studies’ findings demonstrated the effectiveness of the algorithm that was created for keylogger identification. The created method has a high detection rate and a low false alarm rate for keyloggers. The limitation is that all normal applications that hook the system would be flagged as malicious because keylogger behavior is identical to that of programs that hook system message execution.
The authors in [35] created a framework employing a dynamic taint analytical method to identify kernel-level keyloggers. The discovery that kernel keyloggers typically alter the data flow of a keyboard driver in order to capture keystrokes served as the inspiration for the investigation. The framework taints and monitors the keystroke data to identify and analyze any unauthorized uses of the data. Using a system that can allow dynamic taint analysis and perform host-based intrusion detection, the authors created a conceptual model prototype and assessed its efficiency. The experimental outcomes demonstrated that the created system can accurately detect kernel-level keylogging actions and pinpoint their causes. The summary of the relevant works is shown in Table 1.
2.4. Motivation for the Work
The motivation of this study is based on the fact that most keylogger detection techniques still suffer a high false positive rate and low detection accuracy. Most existing techniques also require a lot of computation, and the application of recent machine learning techniques is required for accurate keyloggers detection. Most existing techniques also focus on building keylogger malware rather than keylogger detection mechanisms. Moreso, most of the existing techniques conducted comparative analysis and presented no effective solutions against keyloggers.
3. Materials and Methods
Existing keylogger detection techniques were unable to detect new keylogger attacks using only the signature of keyloggers. This motivated the development of this system to come up with the fusion of signature-based and anomaly-based detection techniques to detect new keylogger attacks.
3.1. Overview of the Proposed Method
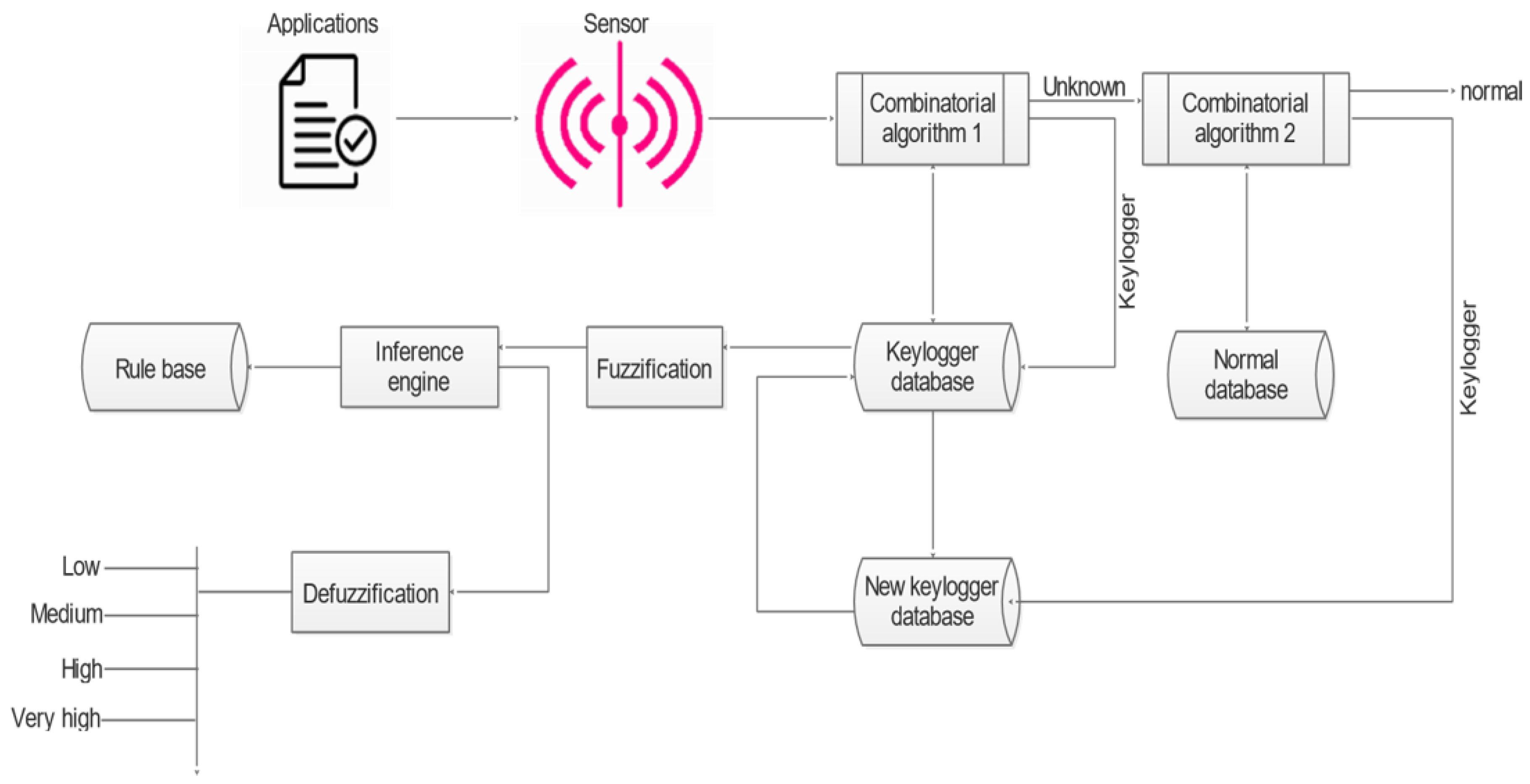
This study developed a combinatorial-based fuzzy inference system for keylogger detection (CaFISKLD). The developed CaFISKLD is divided into three major phases: dataset generation, keylogger detection, and keylogger classification. First, the Java programming language was used to create randomly generated ASCII-coded sequence data. The ASCII-coded sequence data was chosen to replicate the log of keystrokes by keylogger spyware. The generated data was divided into normal and keylogger databases. Second, the generated databases were then fed into a back-to-back combinatorial algorithm to detect keylogger patterns. The first combinatorial algorithm uses the keylogger database to detect keyloggers based on a threshold score. Similarly, the second combinatorial algorithm uses the normal database to detect keyloggers based on a threshold score. The justification for the back-to-back combinatorial algorithms based on the two databases is the combination of the advantages of the signature-based and anomaly-based detection methods. Finally, the detected keyloggers were classified into different severity levels using a fuzzy inference system. Figure 1 describes the architecture of the developed CaFISKLD.
3.2. Design Approach
The developed CaFISKLD is divided into dataset generation, keylogger detection, and keylogger classification.
3.2.1. Dataset Description
The Java programming language randomly generates ASCII-coded sequence data in addition to regular and keylogger sequence data. The ASCII codes were produced between 48 (inclusive) and 91 (exclusive), with ASCII codes between 57 and 65 being excluded. To prevent ASCII codes for special characters, the range between 57 and 65 is the cutoff. To recreate a keylogger spyware’s log of keystrokes, ASCII codes were used. The confirmation of CaFISKLD’s efficiency with text sequences using a combinatorial method is another rationale for utilizing ASCII codes. The newly created CaFISKLD is capable of producing a lot of ASCII-coded sequence data for both the keylogger and regular databases.
3.2.2. Keylogger Detection
- Sensor
The developed CaFISKLD includes a sensor that can extract features in any incoming application to the system. The developed CaFISKLD consists of three databases: a keylogger database, a normal database, and an updated new keylogger database. The keylogger database consists of keylogger signatures that define the sequence of keylogger attacks. The normal database consists of non-keylogger signatures defining normal system activities. Finally, the updated new keylogger database consists of a newly detected keylogger signature that can be used to update the keylogger database. Therefore, the sensor collects feature from any application or activities in the system and transfers control to the combinatorial Algorithm 1.
| Algorithm 1 Combinatorial pattern matching (p, t) |
|
- Combinatorial Algorithm 1
The sensor transfer collects feature patterns of applications running on the system and passes the signal to the combinatorial Algorithm 1 to try to match the feature patterns with the database of known keylogger signatures in the keylogger. The keylogger database represents the signature-based detection of the keylogger. Suppose the feature patterns match any of the patterns in the keylogger database. In that case, a keylogger attack is detected by the combinatorial Algorithm 1, and the application that produces the patterns is blocked. However, if the feature pattern does not match any of the features in the keylogger database, the feature patterns are passed onto a combinatorial Algorithm 2 for anomaly-based detection. Combinatorial Algorithm 2 is in charge of examining and spotting fresh attacks that are not already recorded in the keylogger database.
| Algorithm 2 CaKLDA: Combinatorial Keylogger Detection Algorithm |
|
- Combinatorial Algorithm 2
The adopted combinatorial Algorithm 2 uses the normal database representing anomaly-based detection for the examination of feature patterns that do not match any of the patterns in the keylogger database, so the idea of pattern matching is used.
C.1 Euclidean distance
The Euclidean distance was adapted for the combinatorial algorithms to calculate the separation between the databases and the unknown pattern. If I represents each distinct pattern in the unidentified pattern, then n is its dimension. Equation (1) can then be used to determine the Euclidean distance d between an unknown pattern (t) and a known database (p).
C.2 Scoring system
The combinatorial algorithms use the score from the computed similarities within a given database using the unidentified pattern to determine whether a sequence is from a keylogger or not. The scoring algorithm calculates the similarity scores based on a predetermined threshold value. Equation (2) illustrates the similarity rating.
where Equations (3) and (4) show how to write , respectively.
where denote the degree to which two unrelated, unknown patterns, , respectively, match a specific database, . The average match scores are and , respectively.
The similarity score can be a match score, which, whether expressed as a mismatch score or not, is always positive for a reward of the perfect match between the unknown pattern and a provided database. This is fine for any discrepancy between the unknown pattern’s resemblance to a particular database. The match and mismatch scores in this study rely on the employed threshold values. Based on the accuracy, a threshold value of 12 is chosen. Values that are above the threshold denote matches, whereas values that are below the threshold denote mismatches. A number below the cutoff represents a new keylogger signature to be gathered in the updated database of combinatorial Algorithm 2. Equation (5) can be used to represent combinatorial Algorithm 2’s analytical engine.
C.3 Update new keylogger database
The new, updated keylogger dataset is a separate database used to update the CaFIS-KLD’s keylogger database. A newly discovered keylogger signature from the combinatorial Algorithm 2 analysis is collected and stored in the updated new keylogger database. After the unknown patterns are matched with the standard database, one of two outcomes is produced by the analysis engine of the combinatorial Algorithm 2: keylogger or the standard. The system can use the keylogger decision to update the keylogger database.
3.2.3. Keylogger Classification
The following concepts and terminology of fuzzy logic are applied to the classification of keyloggers.
- Fuzzy set
The fuzzy set for the keylogger classification consists of the following input variables:
- Response time
The slowdown in system performance or online response time can be a determinant for keylogger presence. Response time is simply referred to as time.
- New icons in the system
The presence of unusual icons on the system that the user has not installed previously could indicate the possibility of the presence of a keylogger. The number of new icons in the system is simply referred to as icons.
- A drop in storage space
Keylogger programs normally occupy plenty of space on a computer’s hard drive. Therefore, a sudden drop in storage space could be an indication that a keylogger program is running on the system. A drop in storage space is simply referred to as space.
- Increased hard drive activity
If the hard drive is busy, and the user is not doing anything, the keylogger could send its data to a hacker or upload it to a cloud account. Increased hard drive activity is simply referred to as activity. The fuzzy membership set mentioned in Equation (6) refers to these input variables. The defined membership set’s members are present in varying degrees between 0 and 1.
- Linguistic variables
According to Equation (7), the linguistic variables represent the level of membership for the defined membership set, which is employed to demonstrate the level of categorization for a specific class attribute value. The grades specified in Equation (7) can be assumed by the input and output variables:
- Fuzzification
Equation (8)’s triangle membership function was modified to account for the fact that the linguistic variables are divided into four grades. The crisp values were transformed into fuzzy values by fuzzification. Table 2 displays the fuzzy range of values for the fuzzification process, as calculated by Equation (8). Table 3 also displays the fuzzification process perspective for Equation (8).
where x represents the x-coordinate of real values; a, b, c represents the y-coordinate between 0 and 1; and x represents the real values of the x-coordinate.
- Fuzzy rules
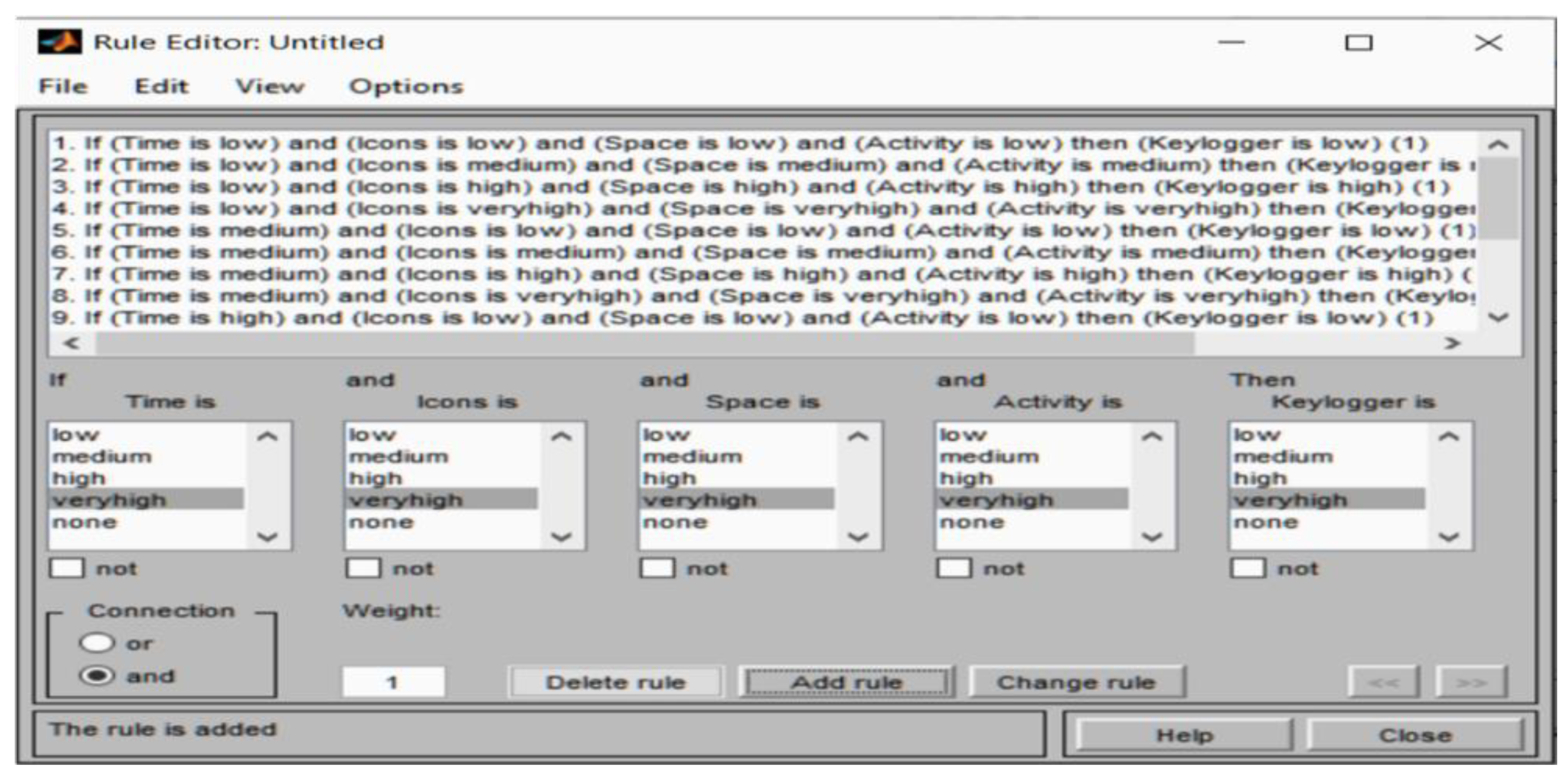
The rule of thumb defined a total of 16 rules. We have 24 = 16 rules because we employed 4 linguistic variables. Table 4 lists the regulations that were developed with the assistance of subject matter specialists. By taking the minimum values, the modified fuzzy logic evaluated its rules using the AND function.
- Inference engine
The idea of fuzzy rules established on the membership set for keylogger classification is used by the fuzzy inference engine. These fuzzy rules are designed to forecast the class for a specific keylogger. The root mean square (RMS) was employed by the fuzzy inference technique to support its conclusions. Equation (9) provides the RMS equation.
R12 + R22 + R32 + ⋯ + Rn2 are values of several rules in the fuzzy rule base that all lead to the same result. Calculate the center of gravity by adding all the results from the same firing rules.
- Defuzzification
The Centre of Gravity (CoG) was adapted as the defuzzification method, as shown in Equation (10). The CoG approach was modified due to its clarity and precision. Defuzzification is the conversion of fuzzy values to clear values for improved human comprehension. The value obtained from the defuzzification process is used to determine the class of a particular keylogger.
where represents the midpoints of each rule’s corresponding fuzzy value range, and symbolizes the root mean square for rules with the same conclusion.
3.2.4. Algorithms
Algorithm 1 presents the original combinatorial algorithm for pattern matching, whereby a given string of text is aligned with a predefined pattern, while Algorithm 2 is the modified combinatorial algorithm for keylogger detection. Algorithm 3 describes the developed classification algorithm for keylogger classification using fuzzy inference system.
| Algorithm 3 FISCA: Fuzzy Inference System Classification Algorithm |
|
4. Implementation, Results, and Discussion
This section presents the implementation and the discussion of the results for the developed CaFISKLD. The keylogger patterns were simulated and tested in real time on the developed algorithm.
4.1. Implementation
The proposed model was implemented on a Windows 10 computer with an Intel Pentium CPU clocked at 2.40 GHz and 4.00 GB of RAM. The experimentation for the developed CaFISKLD was completed using Java programming language. The Integrated Development Environment (IDE) utilized was NetBean, and Notepad++ was used to edit the ASCII-coded sequence data that the Java programming language created at random, in order to model and provide the fuzzy rules for keylogger categorization using MATLAB R2012b.
Training Databases
Figure 2 shows a sample ASCII-coded data sequence for the keylogger database only. The normal database was also generated in a similar fashion but is not shown because of space limitations. Therefore, the keylogger and normal databases serve as the training datasets for the developed CaFISKLD.
- GUI design and partition
The developed CaFISKLD’s graphical user interface (GUI) is depicted in Figure 3. There are top and lower chambers in the GUI. There are three sections in the upper compartment: The phrase “database found” designates either a keylogger database or a regular database as the one in which the pattern was matched. The “traffic class” portion of the match pattern describes if it is a keylogger or a regular pattern. The “threshold and combinatorial score” is the third section in the top compartment. The threshold score is the lowest value for pattern classification; in this research, an accuracy-based cutoff point of 12 was established. In comparison, the combinatorial score is the greatest match score from the second section of the lower compartment. There are two sections in the lower compartment. The first section consists of both typical and keylogger incoming pattern data. The second section is used to calculate the scores of incoming patterns or applications by scanning a regular database or the keylogger database. The system switches to the regular database for score computations if there is no match while searching the keylogger database.
- Training the system
Following each unsuccessful keylogger match result by the combinatorial method, the developed CaFISKLD was trained with the normal database. The normal database’s pattern sequence is a substring of the actual application activity in the computer system. For keylogger detection, combinatorial Algorithm 2 uses the normal database and the unidentified pattern from combinatorial Algorithm 1.
Figure 4 shows how the “perform detection button” in the GUI was used to activate the pattern matching and keylogger detection process. According to the GUI, cyan and green denote genuine positive matches and genuine negative matches, respectively, gray denotes a false negative match, and orange denotes a false positive match.
- Threshold score
The threshold score acts as the lowest level at which a match score value below the threshold value is labeled as a keylogger, utilizing the second iteration of the combinatorial algorithm and treating numbers greater than or equal to the threshold value as the norm. This study chose a threshold value of 12 for sequence matching and keylogger detection based on testing, to obtain the best accuracy.
4.2. Evaluation
Most detection systems employ a confusion matrix as one of their evaluation measures. These parameters were used to assess the accuracy, true positive, true negative, false positive, and false negative performance of CaFISKLD. The performance computations made by CaFISKLD are condensed in the metric equations as follows.
True Positive: The number of accurately predicted keylogger patterns that the algorithm has identified as containing a keylogger is known as a true positive (TP). The characteristics of Equation (11) can be used to define the TP.
where TP stands for “true positives”, and TN stands for “non-keylogger pattern sequence”.
True Negative: The number of accurately predicted non-keylogger patterns that the algorithm has classified as non-keylogger is known as a true negative (TN). The characteristics of Equation (12) can be used to describe TN.
False Positive: The risk that a false alarm may be triggered is known as a false positive (FP). Equation (13) can be used to compute it.
where TN represents the number of true negatives, and FP stands for the number of false positives.
False Negative: The probability that the classifier fails to recognize a true positive is known as a false negative (FN). Equation (14) can be used to compute it.
where TP represents the number of true positives, and FN represents the number of false negatives.
Accuracy: Keylogger patterns that have been correctly identified by the algorithm as including a keylogger are referred to as accurate. Equation (15) can be used to figure out how accurate a keylogger detection is.
where , and .
F1 score: The precision and recall depending on a specific threshold’s harmonic mean is known as the F1 score. It is employed to evaluate the classification’s quality, as shown in Equation (16).
4.3. Results
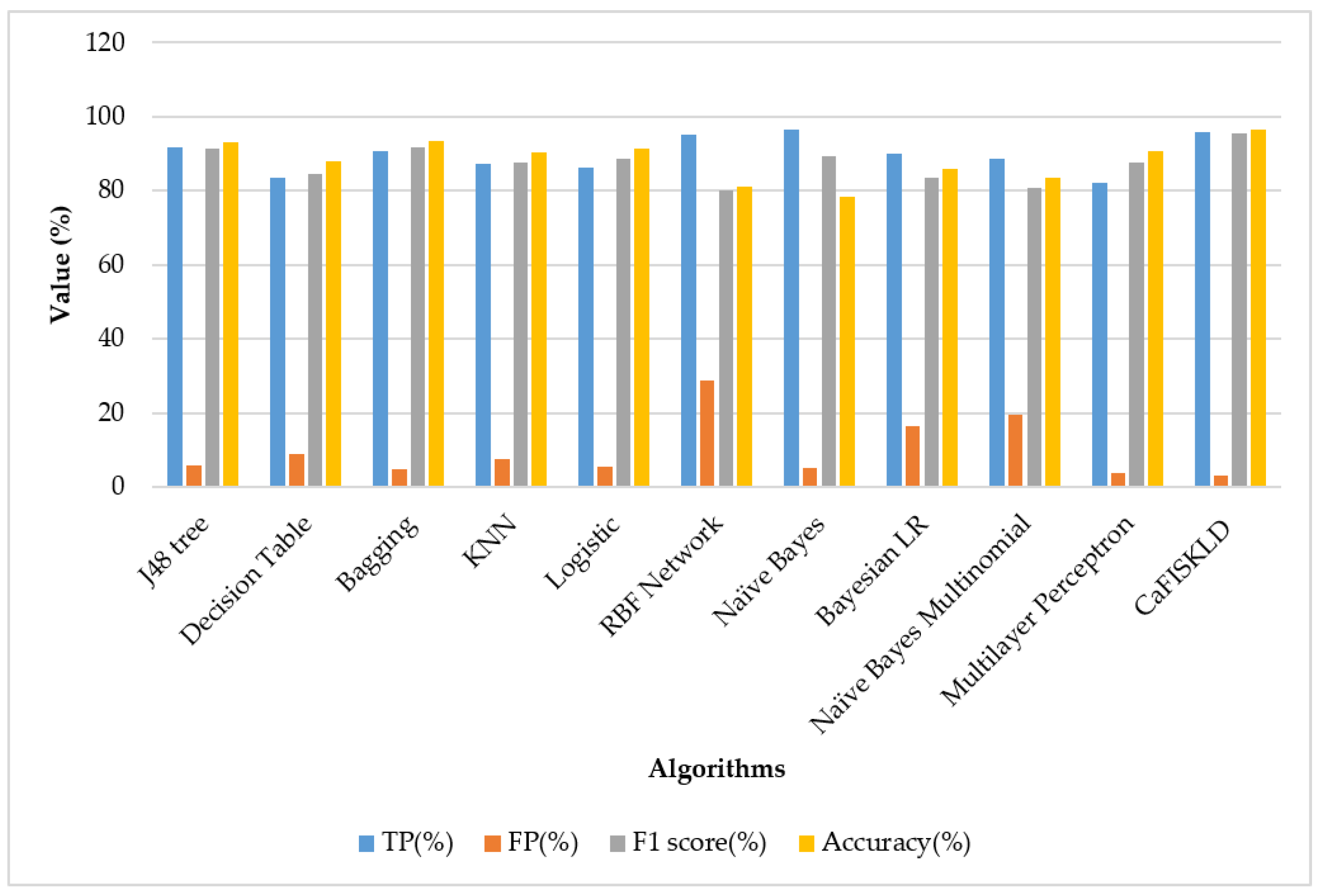
In the literature, most of the studies used machine learning algorithms for keylogger detection; hence, the developed CaFISKLD is compared with machine learning methods on the same dataset. Table 5 shows the confusion matrix of the classification results of the developed CaFISKLD compared with other machine learning algorithms on the same dataset. The simulated keylogger datasets were subjected into the individual machine learning methods and compared separately with the developed CaFISKLD. The results showed that most of the keylogger classes obtained a detection accuracy higher than 78% with all methods. Therefore, the classification results of the developed CaFISKLD compared with each of the other machine learning algorithms are explained below.
- CaFISKLD and J48 tree
The true positive of CaFISKLD is higher than that of the J48 tree, 96% > 91.7%; the false positive of CaFISKLD is lower than that of the J48 tree, 3% < 5.9%; the true negative of CaFISKLD is noticeably higher than that of the J48 tree, 97% > 92%; and the false negative of CaFISKLD is lower than that of the J48 tree, 4% < 6%. The F1 score of CaFISKLD is better, 95.5%, than that of the J48 tree, 91.3%. The accuracy of CaFISKLD is greater than that of the J48 tree, 96.543% > 93.132%. Furthermore, the time taken to build the model of CaFISKLD is lower than that of the J48 tree, 6.22 s < 11.48 s. By looking at the accuracy and time complexity alone, CaFISKLD surpassed the J48 tree. The better performance of CaFISKLD over the J48 tree is due to the efficacy of the combinatorial algorithm for pattern analysis.
- CaFISKLD and the decision table
The true positive of CaFISKLD is higher than that of the decision table, 96% > 83.7%; the false positive of CaFISKLD is lower than that of the decision table, 3% < 9%; the true negative of CaFISKLD is noticeably higher than that of the decision table, 97% > 84%; and the false negative of CaFISKLD is lower than that of the decision table, 4% < 8%. The F1 score of CaFISKLD is better, 95.5%, than that of the decision table, 84.7%. The accuracy of CaFISKLD is greater than that of the decision table, 96.543% > 88.090%. Furthermore, the time taken to build the model of CaFISKLD is less than that of the decision table, 6.22 s < 14.05 s.
- CaFISKLD and bagging
The true positive of CaFISKLD is higher than that of bagging, 96% > 90.7%; the false positive of CaFISKLD is lower than that of bagging, 3% < 4.7%; the true negative of CaFISKLD is noticeably higher than that of bagging, 97% > 91%; and the false negative of CaFISKLD is lower than that of bagging, 4% < 5%. The F1 score of CaFISKLD is better, 95.5%, than that of bagging, 91.6%. The accuracy of CaFISKLD is greater than that of bagging, 96.543% > 93.480%. Furthermore, the time taken to build the model of CaFISKLD is less than that of bagging, 6.22 s < 12.52 s.
- CaFISKLD and KNN
The true positive of CaFISKLD is higher than that of KNN, 96% > 87.3%; the false positive of CaFISKLD is lower than that of KNN, 3% < 7.5%; the true negative of CaFISKLD is noticeably higher than that of KNN, 97% > 88%; and the false negative of CaFISKLD is lower than that of KNN, 4% < 8%. The F1 score of CaFISKLD is better, 95.5%, than that of KNN, 87.8%. The accuracy of CaFISKLD is greater than that of KNN, 96.543% > 90.480%. Furthermore, the time taken to build the model of CaFISKLD was slightly less than that of KNN, 6.22 s < 6.56 s.
- CaFISKLD and logistic regression
The true positive of CaFISKLD is higher than that of logistic regression, 96% > 86.2%; the false positive of CaFISKLD is lower than that of logistic regression, 3% < 5.5%; the true negative of CaFISKLD is noticeably higher than that of logistic regression, 97% > 87%; and the false negative of CaFISKLD is lower than that of logistic regression, 4% < 6%. The F1 score of CaFISKLD is better, 95.5%, than that of logistic regression, 88.6%. The accuracy of CaFISKLD is greater than that of logistic regression, 96.543% > 91.241%. Furthermore, the time taken to build the model of CaFISKLD is less than that of logistic regression, 6.22 s < 11.74 s.
- CaFISKLD and the RBF network
The true positive of CaFISKLD is higher than that of the RBF network, 96% > 95.2%; the false positive of CaFISKLD is far lower than that of the RBF network, 3% < 28.8%; the true negative of CaFISKLD is noticeably the same as that of the RBF network, 97% 97%; and the false negative of CaFISKLD is lower than that of the RBF network, 4% < 29%. The F1 score of CaFISKLD is better, 95.5%, than that of the RBF network, 80.1%. The accuracy of CaFISKLD is greater than that of the RBF network, 96.543% > 81.048%. Furthermore, the time taken to build the model of CaFISKLD is less than that of the RBF network, 6.22 s < 12.44 s.
- CaFISKLD and Naive Bayes
The true positive of CaFISKLD is slightly lower than that of Naive Bayes, 96% < 96.5%; the false positive of CaFISKLD is far lower than that of Naive Bayes, 3% < 5.2%; the true negative of CaFISKLD is noticeably the same as that of Naive Bayes, 97% 97%; and the false negative of CaFISKLD is lower than that of Naive Bayes, 4% < 6%. The F1 score of CaFISKLD is better, 95.5%, than that of Naive Bayes, 89.3%. The accuracy of CaFISKLD is greater than that of Naive Bayes, 96.543% > 78.353%. Furthermore, the time taken to build the model of CaFISKLD is less than that of Naive Bayes, 6.22 s < 10.15 s.
- CaFISKLD and Bayesian LR
The true positive of CaFISKLD is higher than that of Bayesian LR, 96% < 89.9%; the false positive of CaFISKLD is far lower than that of Bayesian LR, 3% < 16.5%; the true negative of CaFISKLD is noticeably higher than that of Bayesian LR, 97% > 90%; and the false negative of CaFISKLD is lower than that of Bayesian LR, 4% < 17%. The F1 score of CaFISKLD is better, 95.5%, than that of Bayesian LR, 83.5%. The accuracy of CaFISKLD is greater than that of Bayesian LR, 96.543% > 85.981%. Furthermore, the time taken to build the model of CaFISKLD is less than that of Bayesian LR, 6.22 s < 10.9 s.
- CaFISKLD and the Naive Bayes multinomial
The true positive of CaFISKLD is higher than that of the Naive Bayes multinomial, 96% > 88.6%; the false positive of CaFISKLD is far lower than that of the Naive Bayes multinomial, 3% < 19.7%; the true negative of CaFISKLD is noticeably higher than that of the Naive Bayes multinomial, 97% > 89%; and the false negative of CaFISKLD is lower than that of the Naive Bayes multinomial, 4% < 20%. The F1 score of CaFISKLD is better, 95.5%, than that of the Naive Bayes multinomial, 80.9%. The accuracy of CaFISKLD is greater than that of the Naive Bayes multinomial, 96.543% > 83.569%. Furthermore, the time taken to build the model of CaFISKLD is less than that of the Naive Bayes multinomial, 6.22 s < 10.13 s.
- CaFISKLD and the Multilayer Perceptron
The true positive of CaFISKLD is slightly higher than that of the Multilayer Perceptron, 96% > 82.2%; the false positive of CaFISKLD is slightly lower than that of the Multilayer Perceptron, 3% < 3.7%; the true negative of CaFISKLD is noticeably higher than that of the Multilayer Perceptron, 97% > 83%; and the false negative of CaFISKLD is the same as that of the Multilayer Perceptron, 4% 4%. The F1 score of CaFISKLD is better, 95.5%, compared to that of the Multilayer Perceptron, 87.5%. The accuracy of CaFISKLD is greater than that of the Multilayer Perceptron, 96.543% > 90.741%. Furthermore, the time taken to build the model of CaFISKLD is less than that of the Multilayer Perceptron, 6.22 s < 62.73 s.
Figure 5 shows a performance comparison based on the true positive, false positive, F1 score, and accuracy metrics. The true positive of CaFISKLD exhibited the highest value, 96%, compared to that of the Multilayer Perceptron, which exhibited the lowest value, 82.2%. Similarly, CaFISKLD showed the best result compared to the RBF network, versus the other methods, in terms of the false positive rate, = 3% and 28.8%, respectively. The accuracy of CaFISKLD showed better results compared to that of Naive Bayes, with values of 96.543 and 78.353, respectively. Hence, bagging showed the closest performances to CaFISKLD with the true positive, false positive, F1 score, and accuracy metrics of 90.7%, 4.7%, 91.6%, and 93.480% and 96%, 3%, 95.5%, and 96.543%, respectively.
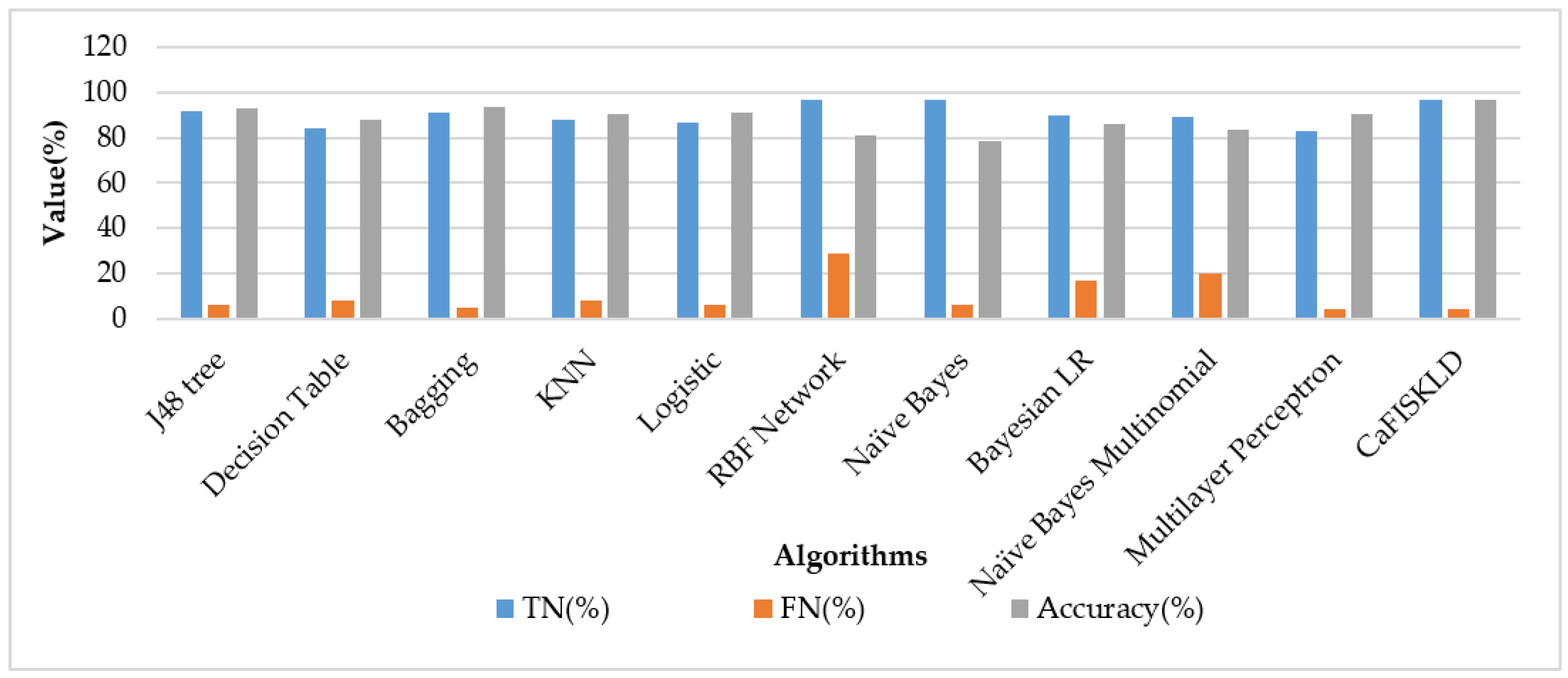
Figure 6 shows the performance comparison based on the true negative, false negative, and accuracy metrics. The true negative of CaFISKLD exhibited the same value as the RBF network and Naive Bayes methods, 97%. CaFISKLD also showed a lower false negative compared to the RBF network and Naive Bayes methods, 4%, 29%, and 6%, respectively. The Multilayer Perceptron showed the lowest values in terms of true negative and false negative, 83% and 4%, respectively.
Figure 7 shows the performance comparison based on the time taken to build the models. The time taken to build the model of CaFISKLD was slightly less than that of KNN, 6.22 s < 6.56 s. The Multilayer Perceptron showed the highest value for the time taken to build the model, 62.73 s. On average, most of the methods took at least 6 s or more to build the models for keylogger detection.
Figure 8 shows the membership function editor for each of the fuzzy variables. This is the editor that enables the definition of linguistic variables for the various fuzzy variables within a specified fuzzy range of values, as indicated by low, medium, high, and very high. These linguistic variables allow for the fuzzification of the fuzzy variables within the specified range of values.
Figure 9 shows the rule editor for the defined fuzzy variables and linguistic variables. The rule editor is where rules are defined and added based on expert knowledge. The rule of thumb defined a total of 16 rules.
4.4. Complexity Analysis
CaFISKLD spends a larger part of its processing time determining if a particular pattern p does not appear at position i in the text t. This test may just require one operation (if ), demonstrating clearly that p does not occur in t at position i, but it may also require up to n operations to complete. As a result, the worst-case running time of CaFISKLD can be calculated as O(nm), where n is the length of the pattern p, and m is the length of the text t.
The running time of CaFISKLD can be computed when finding a pattern in a random text. First, there is a good likelihood that the first test, which compares and results in a mismatch, hence, saving the time that could be spent checking the remaining n − 1 letters of p. Therefore, the time it takes for CaFISKLD to check for a pattern in a text can be estimated as close to the running time of O(m) rather than the worst-case running time of O(nm).
Table 6 shows the rule viewer adjustments and classification decisions. The result of the rule adjustment shows that a keylogger is classified as having a high severity when three of the variables are high and one is average (rule #1). In another test, a keylogger is classified as having a medium severity when three of the variables are low and one is very high (rule #2). In another result, a keylogger is classified as having a very high severity when all the variables are very high (rule #3). Rule #5 showed that a keylogger is classified as having a medium severity when three of the variables are low and one is high. Similarly, a keylogger is classified as having a medium severity when three of the variables are very high and one is low (rule #7). A keylogger is classified as having a low severity when all of the variables are low (rule #10). These results showed that, on average, a successful keylogger attack would produce a medium-severity impact on the system. Hence, the need for the developed CaFISKLD.
4.5. Discussion
Most of the existing works do not provide simulated or benchmark datasets for keylogger detection. Therefore, this study has provided a simulated keylogger patterns based on the ASCII codes generated programmatically. Predominantly, the existing keylogger frameworks cannot detect new keylogger attacks, thereby limiting the keylogger detection frameworks. Therefore, this study has provided the integration of signature-based and anomaly-based keylogger detection frameworks using a back-to-back combinatorial algorithm on a keylogger attack database and normal database, respectively.
The bulk of the existing frameworks did not provide a classification method for the grading of keylogger severity. This study provided a classification algorithm using fuzzy logic to determine each detected keylogger’s severity. The knowledge of the severity grades for keyloggers can assist researchers in understanding the impacts of keyloggers on system resources. This study is also the first to provide color codes for keylogger detection.
4.6. Threats to Validity
The results of the selected related works in this study are assumed to be unbiased and valid. Furthermore, no unpublished works were selected as part of the reviewed related works, since they could invalidate the conclusions obtained by the results of this study. As this study reports the limitations and future research directions that were mentioned in the selected and reviewed studies, the obtained results are impartial and are not tailored to a specific related work.
The reviewed related works were carefully selected among the highly rated and credible articles to ensure the validity of the developed framework in this study. Furthermore, the data simulation in this study using the programmed ASCII-coded sequences was completed in collaboration with experts in keylogger research, so the study did not end with different and contradicting results from the existing related works. Therefore, the threat that could occur due to the personal biases of the authors based on their understanding was resolved.
The threat to the validity of the developed keylogger detection may be unavoidable if a suitable primary related work was missed. However, consistent efforts were made to locate all the relevant studies on keylogger detection published in credible articles, and a rigorous search strategy was adopted to ensure the location of these relevant studies and reduce the threat to the validity of the developed keylogger method. Moreover, each of the selected related works was vetted and evaluated to ensure that it properly represents the area of research on keyloggers, so that the results could be generalized. In addition, the complete description of the developed keylogger method can increase the amount of research on keyloggers using machine learning techniques and give a clear understanding of this study’s reproducibility.
5. Conclusions
Keylogger methods have the limitations of keeping an up-to-date keylogger database, limited research on the simulation of patterns corresponding to keylogger signatures, and low classification accuracy. This study demonstrates that keylogger detection utilizing a combinatorial-based fuzzy inference system can be enhanced regarding classification accuracy and keylogger pattern discovery. This study aims to design a better keylogger detection method based on back-to-back combinatorial algorithms and fuzzy logic. The developed CaFISKLD adopted two back-to-back combinatorial algorithms for matching incoming applications with the keylogger database and analyzing unknown patterns with the normal database. To assess the accuracy and temporal complexity of the created keylogger approach, randomly generated ASCII codes were employed as simulated patterns. The findings demonstrated that the developed CaFISKLD increased the keylogger detection’s precision and employed a threshold setting of 12 to lower the false alarm rate. The developed CaFISKLD also provided the first of its kind: a fuzzy inference system for keylogger classification. In addition, the developed CaFISKLD provided color codes for keylogger detection. In the future, the deep learning method can be adopted as part of the developed model and the extension of the fuzzy logic linguistic variables to enhance keylogger classification.
Author Contributions
The manuscript was written through the contributions of all authors. Conceptualization, F.E.A., J.B.A. and O.A.O.; methodology, J.B.A., O.A.O. and A.L.I.; software, F.E.A., J.B.A. and O.A.O.; validation, J.B.A., O.A.O. and A.L.I.; formal analysis, A.L.I. and C.-T.L.; investigation, J.B.A. and A.L.I.; resources, F.E.A., J.B.A., O.A.O. and C.-T.L.; data curation, F.E.A., J.B.A., C.-C.L. and O.A.O.; writing—original draft preparation, J.B.A., O.A.O. and A.L.I.; writing—review and editing, F.E.A., J.B.A., O.A.O., A.L.I., C.-C.L. and C.-T-L.; visualization, J.B.A., O.A.O., C.-C.L. and A.L.I.; supervision, J.B.A.; project administration, J.B.A., O.A.O. and A.L.I.; funding acquisition, J.B.A. and A.L.I. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Science and Technology Council, Taiwan, R.O.C., under contract no. NSTC 110-2410-H-165-001-MY2. In addition, the work of Agbotiname Lucky Imoize is supported in part by the Nigerian Petroleum Technology Development Fund (PTDF) and in part by the German Academic Exchange Service (DAAD) through the Nigerian-German Postgraduate Programme under grant 57473408.
Data Availability Statement
The data that support the findings of this paper are available upon reasonable request from the first author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sagiroglu, S.; Canbek, G. Keyloggers: Increasing threats to computer security and privacy. IEEE Technol. Soc. Mag. 2009, 28, 10–17. [Google Scholar] [CrossRef]
- Wajahat, A.; Imran, A.; Latif, J.; Nazir, A.; Bilal, A. A Novel Approach of Unprivileged Keylogger Detection. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–6. [Google Scholar]
- Srivastava, M.; Kumari, A.; Dwivedi, K.K.; Jain, S.; Saxena, V. Analysis and Implementation of Novel Keylogger Technique. In Proceedings of the 2021 5th International Conference on Information Systems and Computer Networks (ISCON), Chaumuhan, India, 22–23 October 2021; pp. 1–6. [Google Scholar]
- Rahaman, N.; Rubel, S.; Marouf, A.A. Keylogger Threat to the Android Mobile Banking Applications. In Computer Networks and Inventive Communication Technologies; Springer: Singapore, 2022; pp. 163–174. [Google Scholar]
- Trabelsi, Z.; Saleous, H. Teaching keylogging and network eavesdropping attacks: Student threat and school liability concerns. In Proceedings of the 2018 IEEE Global Engineering Education Conference (EDUCON), Islas Canarias, Spain, 17–20 April 2018; pp. 437–444. [Google Scholar]
- Coombs, E. Human Rights, Privacy Rights, and Technology-Facilitated Violence. In The Emerald International Handbook of Technology-Facilitated Violence and Abuse (Emerald Studies in Digital Crime, Technology and Social Harms); Bailey, J., Flynn, A., Henry, N., Eds.; Emerald Publishing Limited: Bingley, UK, 2021; pp. 475–491. [Google Scholar]
- Awotunde, J.B.; Misra, S. Feature Extraction and Artificial Intelligence-Based Intrusion Detection Model for a Secure Internet of Things Networks. In Illumination of Artificial Intelligence in Cybersecurity and Forensics; Springer: Cham, Switzerland, 2022; pp. 21–44. [Google Scholar]
- Kumar, A.; Dubey, K.K.; Gupta, H.; Memoria, M.; Joshi, K. Keylogger Awareness and Use in Cyber Forensics. In Rising Threats in Expert Applications and Solutions; Springer: Singapore, 2022; pp. 719–725. [Google Scholar]
- Sbai, H.; Goldsmith, M.; Meftali, S.; Happa, J. A survey of keylogger and screenlogger attacks in the banking sector and countermeasures to them. In International Symposium on Cyberspace Safety and Security; Springer: Cham, Switzerland, 2018; pp. 18–32. [Google Scholar]
- Ahmed, Y.A.; Maarof, M.A.; Hassan, F.M.; Abshir, M.M. Survey of Keylogger technologies. Int. J. Comput. Sci. Telecommun. 2014, 5, 25–31. [Google Scholar]
- Datta, P.M. Cybersecurity Threats: Malware in the Code. In Global Technology Management 4.0; Palgrave Macmillan: Cham, Switzerland, 2022; pp. 155–170. [Google Scholar]
- Rawal, B.S.; Manogaran, G.; Peter, A. Hacking for Dummies. In Cybersecurity and Identity Access Management; Springer: Singapore, 2023; pp. 47–62. [Google Scholar]
- An, L.; Yang, G.H. Enhancement of opacity for distributed state estimation in cyber–physical systems. Automatica 2022, 136, 110087. [Google Scholar] [CrossRef]
- Hale, M.T.; Egerstedt, M. Cloud-enabled differentially private multiagent optimization with constraints. IEEE Trans. Control Netw. Syst. 2017, 5, 1693–1706. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E. Forensics and deep learning mechanisms for botnets in internet of things: A survey of challenges and solutions. IEEE Access 2019, 7, 61764–61785. [Google Scholar] [CrossRef]
- Maesschalck, S.; Giotsas, V.; Green, B.; Race, N. Don’t get Stung, cover your ICS in Honey: How do Honeypots fit within Industrial Control System Security. Comput. Secur. 2021, 114, 102598. [Google Scholar] [CrossRef]
- Naït-Abdesselam, F.; Darwaish, A.; Titouna, C. Malware Forensics: Legacy Solutions, Recent Advances, and Future Challenges. In Advances in Computing, Informatics, Networking and Cybersecurity; Springer: Cham, Switzerland, 2022; pp. 685–710. [Google Scholar]
- Pillai, D.; Siddavatam, I. A modified framework to detect keyloggers using machine learning algorithm. Int. J. Inf. Technol. 2019, 11, 707–712. [Google Scholar] [CrossRef]
- Royo, Á.A.; Rubio, M.S.; Fuertes, W.; Cuervo, M.C.; Estrada, C.A.; Toulkeridis, T. Malware Security Evasion Techniques: An Original Keylogger Implementation. In World Conference on Information Systems and Technologies; Springer: Cham, Switzerland, 2021; pp. 375–384. [Google Scholar]
- Ayo, F.E.; Folorunso, S.O.; Abayomi-Alli, A.A.; Adekunle, A.O.; Awotunde, J.B. Network intrusion detection based on deep learning model optimized with rule-based hybrid feature selection. Inf. Secur. J. A Glob. Perspect. 2020, 29, 267–283. [Google Scholar] [CrossRef]
- Meteriz-Yıldıran, Ü.; Yıldıran, N.F.; Awad, A.; Mohaisen, D. A Keylogging Inference Attack on Air-Tapping Keyboards in Virtual Environments. In Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Christchurch, New Zealand, 12–16 March 2022; pp. 765–774. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Manesh, M.R.; Kaabouch, N. Cyber-attacks on unmanned aerial system networks: Detection, countermeasure, and future research directions. Comput. Secur. 2019, 85, 386–401. [Google Scholar] [CrossRef]
- Solairaj, A.; Prabanand, S.C.; Mathalairaj, J.; Prathap, C.; Vignesh, L.S. Keyloggers software detection techniques. In Proceedings of the 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 7–8 January 2016; pp. 1–6. [Google Scholar]
- Folorunso, O.; Ayo, F.E.; Babalola, Y.E. Ca-NIDS: A network intrusion detection system using combinatorial algorithm approach. J. Inf. Priv. Secur. 2016, 12, 181–196. [Google Scholar] [CrossRef]
- Damopoulos, D.; Kambourakis, G.; Gritzalis, S. From keyloggers to touchloggers: Take the rough with the smooth. Comput. Secur. 2013, 32, 102–114. [Google Scholar] [CrossRef]
- Sapra, K.; Husain, B.; Brooks, R.; Smith, M. Circumventing keyloggers and screendumps. In Proceedings of the 2013 8th International Conference on Malicious and Unwanted Software: “The Americas” (MALWARE), Fajardo, PR, USA, 22–24 October 2013; pp. 103–108. [Google Scholar]
- Gunalakshmii, S.; Ezhumalai, P. Mobile keylogger detection using machine learning technique. In Proceedings of the IEEE International Conference on Computer Communication and Systems ICCCS14, Chennai, India, 20–21 February 2014; pp. 51–56. [Google Scholar]
- Case, A.; Maggio, R.D.; Firoz-Ul-Amin, M.; Jalalzai, M.M.; Ali-Gombe, A.; Sun, M.; Richard, G.G., III. Hooktracer: Automatic detection and analysis of keystroke loggers using memory forensics. Comput. Secur. 2020, 96, 101872. [Google Scholar] [CrossRef]
- Aslam, M.; Idrees, R.N.; Baig, M.M.; Arshad, M.A. Anti-hook shield against the software key loggers. In Proceedings of the 2004 National Conference on Emerging Technologies, Cork, Ireland, 26–29 July 2004; pp. 189–191. [Google Scholar]
- Simms, S.; Maxwell, M.; Johnson, S.; Rrushi, J. Keylogger detection using a decoy keyboard. In IFIP Annual Conference on Data and Applications Security and Privacy; Springer: Cham, Switzerland, 2017; pp. 433–452. [Google Scholar]
- Ortolani, S.; Giuffrida, C.; Crispo, B. KLIMAX: Profiling memory write patterns to detect keystroke-harvesting malware. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2011; pp. 81–100. [Google Scholar]
- Sreenivas, R.S.; Anitha, R. Detecting keyloggers based on traffic analysis with periodic behaviour. Netw. Secur. 2011, 2011, 14–19. [Google Scholar] [CrossRef]
- Fu, J.; Liang, Y.; Tan, C.; Xiong, X. Detecting software keyloggers with dendritic cell algorithm. In Proceedings of the 2010 International Conference on Communications and Mobile Computing, Shenzhen, China, 12–14 April 2010; Volume 1, pp. 111–115. [Google Scholar]
- Le, D.; Yue, C.; Smart, T.; Wang, H. Detecting Kernel Level Keyloggers through Dynamic Taint Analysis; College of William & Mary, Department of Computer Science: Williamsburg, VA, USA, 2008. [Google Scholar]
Figure 1.
A combinatorial-based fuzzy inference system architecture for keylogger detection.

Figure 2.
GUI for ASCII-coded Data.

Figure 3.
GUI for CaFISKLD.

Figure 4.
CaFISKLD score computation.

Figure 5.
Performance comparison based on true positive, false positive, F1 score, and accuracy.

Figure 6.
Performance comparison based on true negative, false negative, and accuracy.

Figure 7.
Performance comparison based on the time taken to build the models.

Figure 8.
Membership function editor.

Figure 9.
Rule editor.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of related works.
| Author | Method | Strength | Weakness |
|---|---|---|---|
| Sbai et al. (2018) [9] | Optical Character Recognition (OCR) | −Provides a comparative analysis of OCR systems −Provides countermeasures to keyloggers process | −Not a completely effective solution against keyloggers |
| Gunalakshmii and Ezhumalai (2014) [28] | Support Vector Machine algorithm | −Avoids the over-fitting problem −Provides a mobile-based application | −High expense of learning several support vectors −Detection phase moves slowly |
| Damopoulos et al. (2013) [26] | Machine learning approach | −Direct record of every keystroke on the touch devices −Compares the accuracies of machine learning algorithms −Collection of keyloggers profiles | −No formal method for keyloggers’ detection −Low classification speed −Long learning time |
| Pillai and Siddavatam (2019) [18] | Modified Support Vector Machine algorithm | −Good classification accuracy −Provides I/O hook mechanism | −Framework is not generic to all applications |
| Wajahat et al. (2019) [2] | Unprivileged keylogger detection | −Can detect a user space keylogger −Offers protection to information system | −Limited in the application of intelligent systems to keyloggers |
| Case et al. (2020) [29] | Hook tracer | −Automated keylogger detection −Scalable | −Reverse engineering of the method exhibited malicious behaviors −Low classification accuracy |
| Simms et al. (2017) [31] | Decoy keyboard | −Decent detection precision −Secure to use −Does not obstruct the user’s work | −Limited in the application of intelligent systems to keyloggers |
| Meteriz-Yıldıran et al. (2022) [21] | Keylogging inference attack | −Achieved the best accuracy for inferring the keystrokes from the user’s hand movement | −Focused on building Keylogger rather than keylogger detection |
| Royo et al. (2021) [19] | Malware security evasion techniques | −Successfully gathered confidential information | −Focused on building Keylogger rather than keylogger detection |
| Ortolani et al. (2011) [32] | Behavior-based detection technique | −Allows for no false negatives −Possible to classify and analyze malware on a wide scale | −Not concerned with malware resistance strategies that hide or postpone data leakage |
| Sreenivas and Anitha (2011) [33] | Anomaly-based detection mechanism | −Provides an accurate keyloggers detection using traffic analysis −Generic for other applications | −For erratic time intervals, there is a lack of quantitative analysis |
| Fu et al. (2010) [34] | Dendritic cell algorithm | −High detection rate −Low false alarm rate | −Keylogger behavior is the same as that of programs that hook system message execution −The system would identify all normal programs that attach it as malicious |
| Le et al. (2008) [35] | Dynamic taint analysis technique | −Accurate detection of kernel level keylogging activities −Identifies the root causes of a detected keylogger | −Integration with modern methods is required |
| Aslam et al. (2004) [30] | Anti-hook technique | −Simple to find all suspicious files at an application level | −A lot of computation involved. −A lot of false positives occur |
Table 2.
Fuzzy value range.
| Linguistic Value | Value Range |
|---|---|
| 1. Low | 0.1 ≤ x < 0.3 |
| 2. Medium | 0.3 ≤ x < 0.6 |
| 3. High | 0.6 ≤ x < 0.8 |
| 4. Very high | 0.8 ≤ x ≤ 1.0 |
Table 3.
Fuzzification process view.
| Linguistic Value | ||||
|---|---|---|---|---|
| Low | 0, if = 0.1 | , if [0.1, 0.3] | , if [0.2, 0.3] | 0, if ≥ 0.3 |
| Medium | 0, if = 0.3 | , if [0.3, 0.6] | , if [0.45,0.6] | 0, if ≥ 0.6 |
| High | 0, if = 0.6 | , if [0.6, 0.8] | , if [0.7, 0.8] | 0, if ≥ 0.8 |
| Very high | 0, if = 0.8 | , if [0.8, 1.0] | , if [0.9, 1.0] | 0, if ≥ 1.0 |
Table 4.
Sample rule base for keylogger classification.
| #No | Time | Icons | Space | Activity | Keylogger Classification (Conclusion) | Non Zero Min No. |
|---|---|---|---|---|---|---|
| 1 | 0.25 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 2 | 0.25 | 0.5 | 0.5 | 0.5 | Medium | 0.25 |
| 3 | 0.25 | 0.75 | 0.75 | 0.75 | High | 0.25 |
| 4 | 0.25 | 0.9 | 0.9 | 0.9 | High | 0.25 |
| 5 | 0.5 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 6 | 0.5 | 0.5 | 0.5 | 0.5 | Medium | 0.5 |
| 7 | 0.5 | 0.75 | 0.75 | 0.75 | High | 0.5 |
| 8 | 0.5 | 0.9 | 0.9 | 0.9 | Very high | 0.5 |
| 9 | 0.75 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 10 | 0.75 | 0.5 | 0.5 | 0.5 | Medium | 0.5 |
| 11 | 0.75 | 0.75 | 0.75 | 0.75 | High | 0.75 |
| 12 | 0.75 | 0.9 | 0.9 | 0.9 | Very high | 0.75 |
| 13 | 0.9 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 14 | 0.9 | 0.5 | 0.5 | 0.5 | Medium | 0.5 |
| 15 | 0.9 | 0.75 | 0.75 | 0.75 | High | 0.75 |
| 16 | 0.9 | 0.9 | 0.9 | 0.9 | Very high | 0.9 |
Table 5.
Performance comparisons.
| Algorithm | TP (%) | FP (%) | TN (%) | FN (%) | F1 score | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| J48 tree | 91.7 | 5.9 | 92 | 6 | 91.3 | 93.132 | 11.48 |
| Decision table | 83.7 | 9 | 84 | 8 | 84.7 | 88.090 | 14.05 |
| Bagging | 90.7 | 4.7 | 91 | 5 | 91.6 | 93.480 | 12.52 |
| KNN | 87.3 | 7.5 | 88 | 8 | 87.8 | 90.480 | 6.56 |
| Logistic regression | 86.2 | 5.5 | 87 | 6 | 88.6 | 91.241 | 11.74 |
| RBF network | 95.2 | 28.8 | 97 | 29 | 80.1 | 81.048 | 12.44 |
| Naive Bayes | 96.5 | 5.2 | 97 | 6 | 89.3 | 78.353 | 10.15 |
| Bayesian Logistic Regression (Bayesian LR) | 89.9 | 16.5 | 90 | 17 | 83.5 | 85.981 | 10.9 |
| Naive Bayes Multinomial | 88.6 | 19.7 | 89 | 20 | 80.9 | 83.569 | 10.13 |
| Multilayer Perceptron | 82.2 | 3.7 | 83 | 4 | 87.5 | 90.741 | 62.73 |
| CaFISKLD | 96 | 3 | 97 | 4 | 95.5 | 96.543 | 6.22 |
Table 6.
Rule viewer adjustment and classification.
| No | Time | Icons | Space | Activity | Fuzzy Value |
|---|---|---|---|---|---|
| 1 | 0.72 | 0.777 | 0.735 | 0.5 | High |
| 2 | 0.129 | 0.177 | 0.417 | 0.854 | Medium |
| 3 | 0.932 | 0.962 | 0.932 | 0.915 | Very high |
| 4 | 0.932 | 0.192 | 0.189 | 0.485 | Low |
| 5 | 0.265 | 0.254 | 0.705 | 0.3 | Medium |
| 6 | 0.0833 | 0.715 | 0.0682 | 0.0846 | Medium |
| 7 | 0.962 | 0.946 | 0.886 | 0.1 | Medium |
| 8 | 0.962 | 0.946 | 0.886 | 0.823 | High |
| 9 | 0.644 | 0.638 | 0.689 | 0.669 | High |
| 10 | 0.0985 | 0.0692 | 0.0985 | 0.192 | Low |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ayo, F.E.; Awotunde, J.B.; Olalekan, O.A.; Imoize, A.L.; Li, C.-T.; Lee, C.-C. CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection. Mathematics 2023, 11, 1899. https://doi.org/10.3390/math11081899
AMA Style
Ayo FE, Awotunde JB, Olalekan OA, Imoize AL, Li C-T, Lee C-C. CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection. Mathematics. 2023; 11(8):1899. https://doi.org/10.3390/math11081899
Chicago/Turabian StyleAyo, Femi Emmanuel, Joseph Bamidele Awotunde, Olasupo Ahmed Olalekan, Agbotiname Lucky Imoize, Chun-Ta Li, and Cheng-Chi Lee. 2023. "CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection" Mathematics 11, no. 8: 1899. https://doi.org/10.3390/math11081899
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.